
Social (media) listening is a term most frequently used in marketing to denote a process through which one can identify what is being said about a certain brand, product, service or topic. Marketing agencies and companies used it to acquire competitor intelligence, see how the public perceives their new product and follow the latest industry trends. Broadly speaking, by following certain keywords, they weave a net to “catch” the conversations happening online that pertain to the specific area of interest. These statements in these conversations are then analysed using algorithms that determine sentiment, and the data is gathered to show how consumers/users are influenced by their marketing efforts. Next time you post about a good or bad experience you had using, for example, a streaming service, chances are that your opinion will be registered in their database.
When it comes to social listening in the social sciences sphere, the instrument serves a similar purpose – it can show researchers how the public perceives new policies or, as is case for AI, recent technological developments that would need to be regulated.
In the popAI project, the European Citizen Action Service (ECAS) is in charge of bringing the citizens’ perspective in understanding how people perceive AI tools being employed by law enforcement agencies (LEAs). For this, ECAS employs a multi-layered approach, combining both proactive tools (our crowdsourcing platform that you can still contribute to) and passive ones, like the social listening.
In the introduction above, it was mentioned that social listening is used by marketing professionals for their business purposes. Using mainly data from social media platforms, this allows them to then target users with very specific interests, maybe even specific people themselves for future campaigns. In popAI, ECAS makes use of ethical social listening, which does not collect any data about the individuals, but is only interested in the content of the messages or conversations themselves. This prevents any possible biases about the data and respects the privacy of the people who voiced the opinions.
To analyse data, of course, one must first get it from somewhere. For the purposes of our social listening, we use the CommonCrawl database for the years 2013-2021, which “crawls” and records the internet – blogs, publications, research papers, news articles and everything else except for social media. We then cast our net of keywords that identify AI tools (e.g biometric identification) and aspects of possible concern about them (e.g privacy, accountability). Any opinion that is present in the CommonCrawl database and matches our keywords becomes part of our dataset and is filed accordingly. Up to this point, we’ve gathered relevant results and can track the volume of conversations that happened over time, due to their timestamps. One thing that is missing is the sentiment. How do we understand if an opinion is positive, negative or neutral and how can we make conclusions on the overall disposition of the public towards the topic of interest? For this, we use a language model, which was trained on millions of texts to determine sentiment in numerical format, from -1 (the most negative) to 1 (the most positive) and decimal numbers in between.
Below is a presentation of the most interesting results, in preparation of publishing the full report on the social listening activity. Check out the popAI website and social media accounts regularly to find out when it comes out.
We searched for the following AI tools that can be used by law enforcement:
For each of those tools, we wanted to find out the sentiment as they relate to the following areas of possible concern to citizens:
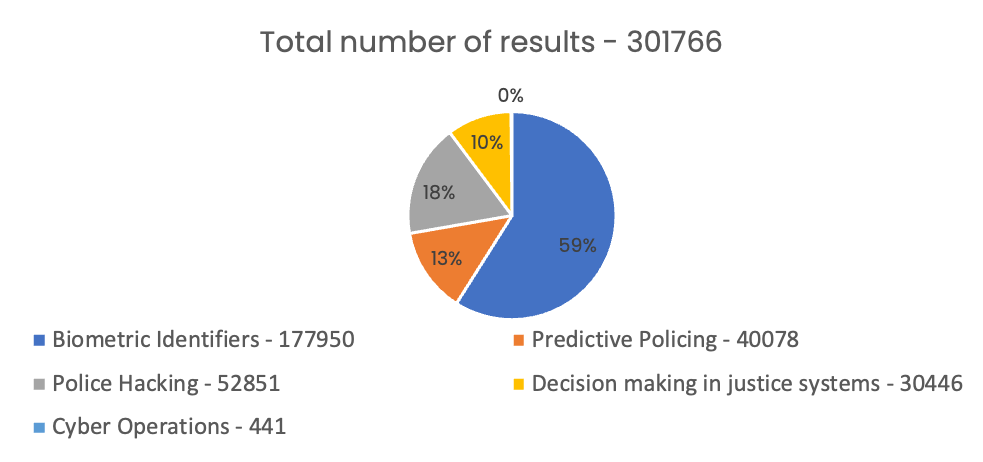
Firstly, let us take a look at the topics that generate most conversations online. By far the biggest leader is Biometric Identifiers with more than 50% of the total results, followed by police hacking and predictive policing. Cyber operations brought a total of 441, which is statistically irrelevant and is below 1% of all results.
In order to be able to visually follow the trends over time, we’ve created a digital dashboard that includes each topic and its subtopics and their progression from 2013 to 2021. It charts both the number of conversations happening year-to-year and the average sentiment for the year. Some of the most interesting findings are presented and explained below:
Although all topics generate a lot of neutral and negative sentiment, and much less positive, there is one subtopic that distributes sentiment equally, namely “Efficiency, Reliability and Accuracy”. This shows that, while people do have a great sensitivity of the negative ways that AI can impact their lives and privacy, they are also distinctly aware of the potential positive uses of such tools in the work of police, if wielded ethically.
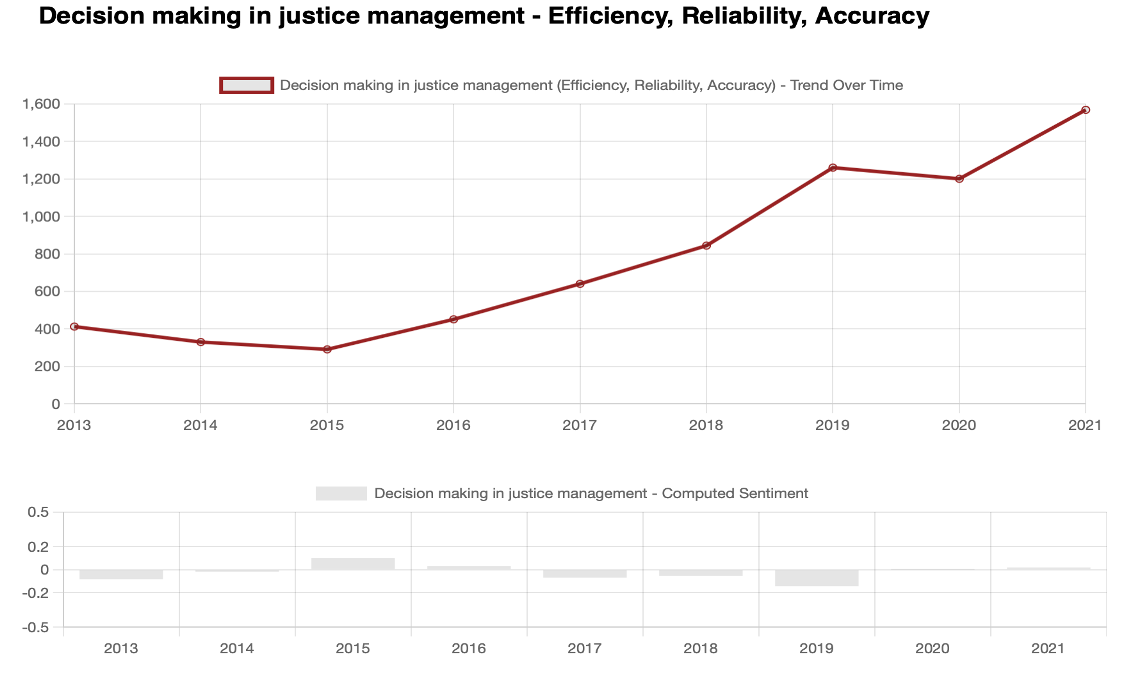
We can take “Efficiency, Reliability and Accuracy” under the topic of AI in justice systems. The bars below show that the average estimate ranges somewhere between -0.2 and +0.2, which means neutrality.
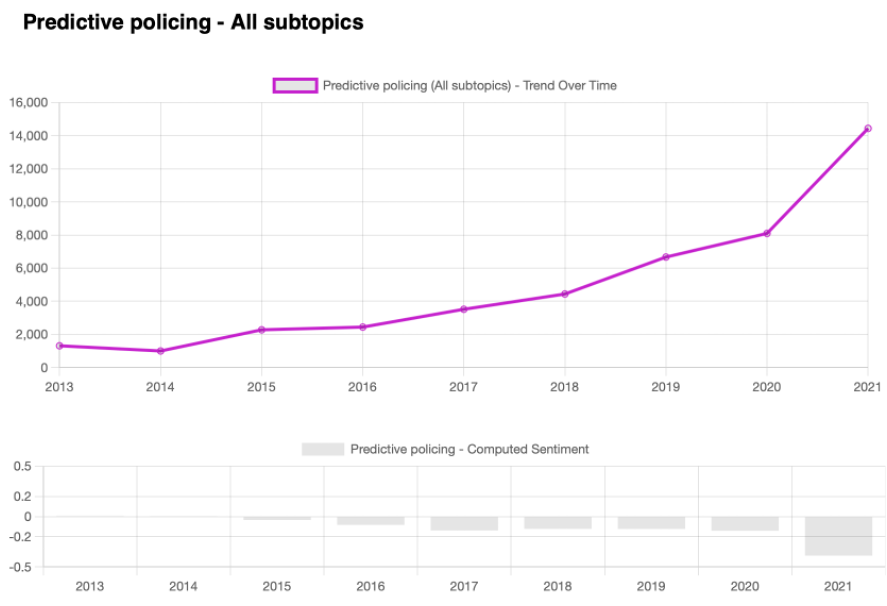
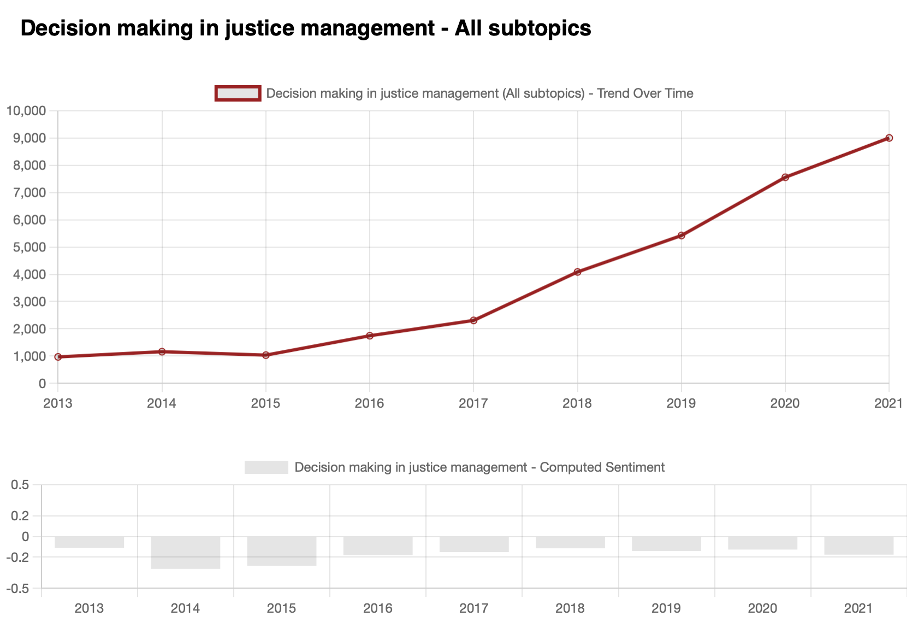
Another trend can be found when viewing the number of conversations centered around the topics of “Predictive Policing” and “Decision making in the justice system”. While both are not the most popular in absolute terms, they are showing a steady progression towards generating more and more interest. When it comes to “Predictive policing” though, it is being discussed with ever more negative feelings.
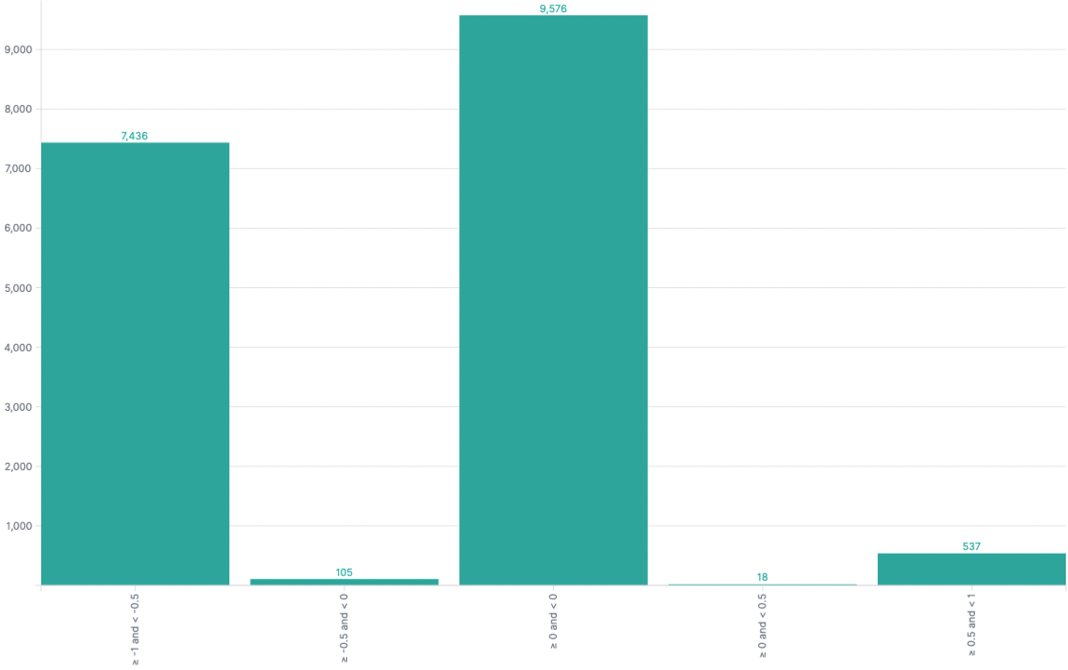
Lastly, an interesting result comes up when we look at the sentiment distribution for “Biometric identifiers”, subtopic “Privacy”. The research team went out with the expectation that this would be the most negatively discussed aspect under “Biometric Identifiers”. While it did indeed generate a lot of results (more than 66,000), the vast majority of them were neutral (more than 52,000). One possible explanation for this could be the adoption of biometric identification tools in many consumer goods, such as phones, which makes people more accepting to them in the police work as well. Still, there’s a notably negative sentiment when it comes to whether these tools lead to discrimination. Strongly negative opinions are almost half of all found, represented by the left-most column in the graph below.
The social listening activity gave the popAI project valuable insight into the feelings of people towards artificial intelligence being used by law enforcement agencies. Taking this knowledge, we can now move to the next phase – asking citizens about their ideas on how these concerns can be fixed. Based on the crowdsourcing questions and the data from the ethical social listening, we want to hear citizen’s solutions and recommendations in three key areas: